Kernel-based Time-varying Regression - Part I¶
Kernel-based time-varying regression (KTR) is a time series model to address
time-varying regression coefficients
complex seasonality pattern
The full details of the model structure with an application in marketing media mix modeling can be found in Ng, Wang and Dai (2021). The core of KTR is the use of latent variables to define a smooth time varying representation of model coefficients, which bears a similar ideas in Kernel Smoothsing. The KTR approach sharply reduces the number of parameters compared to typical dynamic linear models such as Harvey (1989), and Durbin and Koopman (2002). The reduced number of parameters improves the computation speed, and allows for handling of high dimensional data and detecting small variances.
To topics covered here in Part I, are
KTR model structure
syntax to initialize, fit and predict a model
fit a model with complex seasonality
visualization of prediction and decomposed components
[1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import orbit
from orbit.models import KTR
from orbit.diagnostics.plot import plot_predicted_data, plot_predicted_components
from orbit.utils.dataset import load_electricity_demand
%matplotlib inline
pd.set_option('display.float_format', lambda x: '%.5f' % x)
[2]:
print(orbit.__version__)
1.1.4.6
Model Structure¶
This section gives the mathematical structure of the KTR model. In short, it considers a time-series (\(y_t\)) as the linear combination of three parts which are the local-trend (\(l_t\)), seasonality (\(s_t\)), and regression (\(r_t\)) terms. Mathematically,
where the \(\epsilon_t\) comprise a stationary random error process.
In KTR, the distinction between the local-trend, seasonality, and regressors while useful is semi-arbitrary and the time-series can also be considered as
where \(\beta_t\) is a \(P\)-dimensional vector of coefficients that vary over time (i.e., \(\beta_i\) is almost certainly different from \(\beta_j\) for \(i \neq j\)) and \(X_t\) \(P\)-dimensional covariate vector (i.e., the \(t\)th row of \(X\), the design matrix).
To reduce the total number of parameters in the model (potentially \(P \times T\)) the \(\beta_t\) are parameterized with a weighted sum of \(J\) local latent variables (\(b_1,..b_j,..b_J\)). That is
where
coefficient matrix \(B\) has size \(T \times P\) with rows equal to the \(\beta_t\).
knot matrix \(b\) with size \(P\times J\); each entry is a latent variable \(b_{p, j}\). The \(b_j\) can be viewed as the “knots” from the perspective of spline regression and \(j\) is a time index such that \(t_j \in [1, \cdots, T]\).
kernel matrix \(K\) with size \(T\times J\) where the \(i\)th row and \(j\)th element can be viewed as the normalized weight \(k(t_j, t) / \sum_{j=1}^{J} k(t_j, t)\)
For the level/trend,
It can also be viewed as a dynamic intercept (where the regressor is a vector of ones).
For the seasonality,
We use Fourier series to handle the seasonality; i.e., sin waves with varying periods are used for the columns of \(X_{ \text{seas}}\).
The details for the additional regressors are given in Part II, as they are not used in this tutorial. Note this includes different choices of kernel function (which determines the kernel matrix \(K\)) and prior for matrix \(b\).
Data¶
To illustrate the usage of KTR, consider the daily series of electricity demand in Turkey from the 2000 - 2008.
[3]:
# from 2000-01-01 to 2008-12-31
df = load_electricity_demand()
date_col = 'date'
response_col = 'electricity'
df[response_col] = np.log(df[response_col])
print(df.shape)
df.head()
(3288, 2)
[3]:
| date | electricity | |
|---|---|---|
| 0 | 2000-01-01 | 9.43760 |
| 1 | 2000-01-02 | 9.50130 |
| 2 | 2000-01-03 | 9.63565 |
| 3 | 2000-01-04 | 9.65392 |
| 4 | 2000-01-05 | 9.66089 |
[4]:
print(f'starts with {df[date_col].min()}\nends with {df[date_col].max()}\nshape: {df.shape}')
starts with 2000-01-01 00:00:00
ends with 2008-12-31 00:00:00
shape: (3288, 2)
Train / Test Split¶
Split the data into a training set and test set for model validation.
[5]:
test_size=365
train_df=df[:-test_size]
test_df=df[-test_size:]
A Quick Start on KTR¶
Here the Similar to other model types in Orbit, KTR follows sklearn model API style. First an instance of the Orbit class KTR is created. Second fit and predict methods are called for that instance. Note that unlike version <=1.0.15, the fitting API arg are within the function; thus, KTR is called directly.
[6]:
ktr = KTR(
response_col=response_col,
date_col=date_col,
seed=2021,
estimator='pyro-svi',
# bootstrap sampling to capture uncertainties
n_bootstrap_draws=1e4,
# pyro training config
num_steps=301,
message=100,
)
[7]:
ktr.fit(train_df)
2024-03-19 23:38:25 - orbit - INFO - Optimizing (CmdStanPy) with algorithm: LBFGS.
2024-03-19 23:38:25 - orbit - INFO - Using SVI (Pyro) with steps: 301, samples: 100, learning rate: 0.1, learning_rate_total_decay: 1.0 and particles: 100.
/Users/towinazure/opt/miniconda3/envs/orbit311/lib/python3.11/site-packages/torch/__init__.py:696: UserWarning: torch.set_default_tensor_type() is deprecated as of PyTorch 2.1, please use torch.set_default_dtype() and torch.set_default_device() as alternatives. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/torch/csrc/tensor/python_tensor.cpp:453.)
_C._set_default_tensor_type(t)
2024-03-19 23:38:26 - orbit - INFO - step 0 loss = -1946.6, scale = 0.093118
INFO:orbit:step 0 loss = -1946.6, scale = 0.093118
2024-03-19 23:38:29 - orbit - INFO - step 100 loss = -3131.7, scale = 0.01002
INFO:orbit:step 100 loss = -3131.7, scale = 0.01002
2024-03-19 23:38:32 - orbit - INFO - step 200 loss = -3132, scale = 0.010005
INFO:orbit:step 200 loss = -3132, scale = 0.010005
2024-03-19 23:38:35 - orbit - INFO - step 300 loss = -3121.6, scale = 0.0098163
INFO:orbit:step 300 loss = -3121.6, scale = 0.0098163
[7]:
<orbit.forecaster.svi.SVIForecaster at 0x15e870c90>
We can take a look how the level is fitted with the data.
[8]:
predicted_df = ktr.predict(df=df)
predicted_df.head()
[8]:
| date | prediction_5 | prediction | prediction_95 | |
|---|---|---|---|---|
| 0 | 2000-01-01 | 9.48516 | 9.61908 | 9.75428 |
| 1 | 2000-01-02 | 9.48116 | 9.61605 | 9.75010 |
| 2 | 2000-01-03 | 9.48156 | 9.61657 | 9.74966 |
| 3 | 2000-01-04 | 9.48273 | 9.61614 | 9.75022 |
| 4 | 2000-01-05 | 9.47921 | 9.61620 | 9.75183 |
One can use .get_posterior_samples() to extract the samples for all sampling parameters.
[9]:
ktr.get_posterior_samples().keys()
[9]:
dict_keys(['lev_knot', 'lev', 'yhat', 'obs_scale'])
[10]:
_ = plot_predicted_data(training_actual_df=train_df, predicted_df=predicted_df,
date_col=date_col, actual_col=response_col,
test_actual_df=test_df, markersize=20, lw=.5)
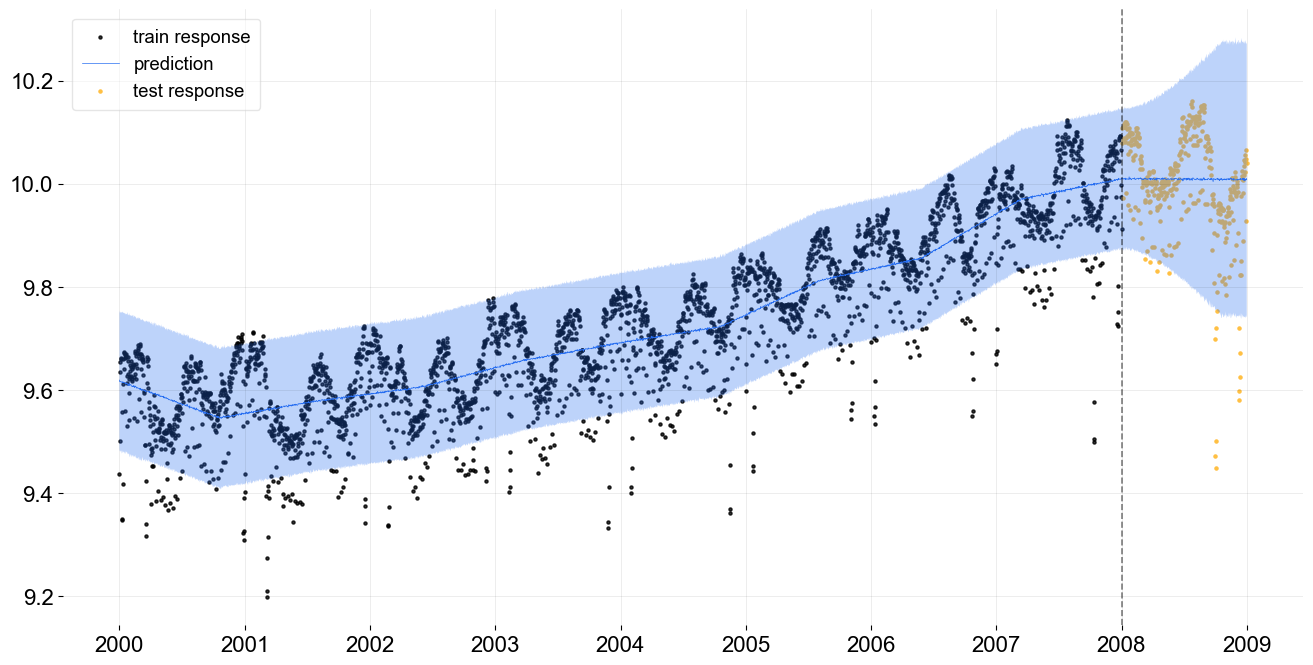
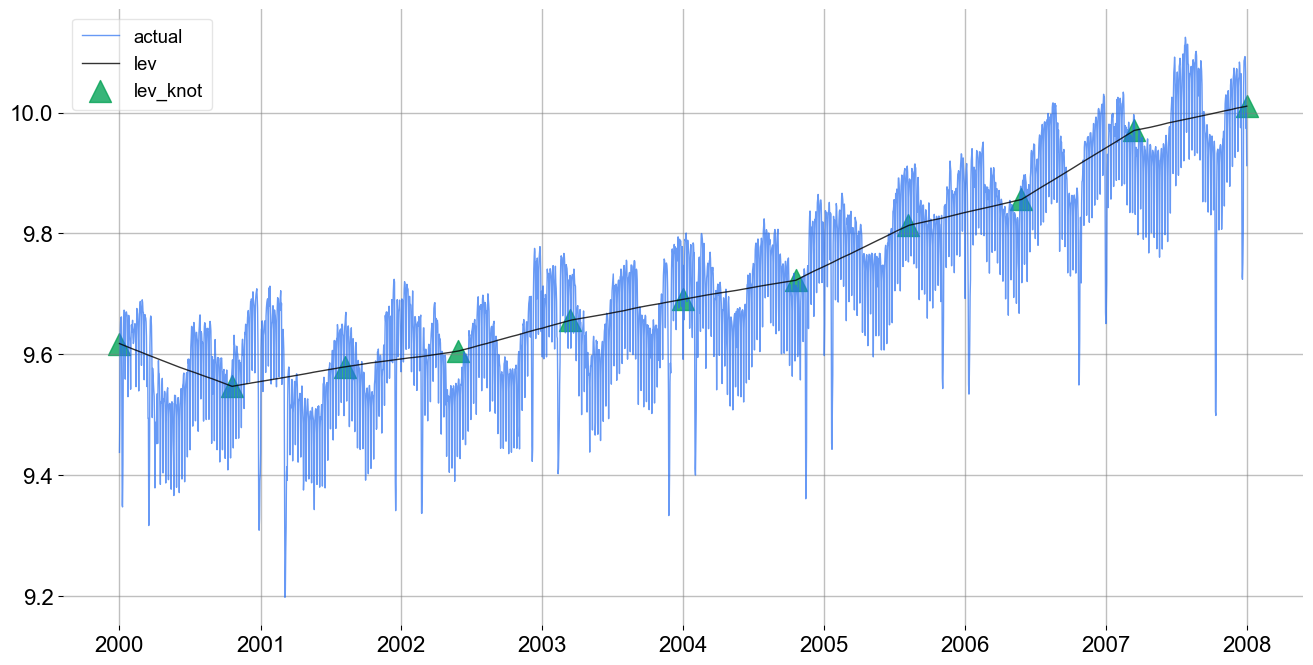
It can also be helpful to see the trend knot locations and levels. This is done with the plot_lev_knots function.
[11]:
_ = ktr.plot_lev_knots()
Fitting with Complex Seasonality¶
The previous model fit is not satisfactory as there is clear seasonality in the electrical demand time-series that is not accounted for. In this modelling example the electrical demand data is fit with a dual seasonality for weekly and yearly patterns. Since the data is daily, the seasonality periods are 7 and 365.25. These are added into the KTR object as a list through the seasonality arg. Otherwise the process is the same as the previous example.
[12]:
ktr_with_seas = KTR(
response_col=response_col,
date_col=date_col,
seed=2021,
seasonality=[7, 365.25],
estimator='pyro-svi',
n_bootstrap_draws=1e4,
# pyro training config
num_steps=301,
message=100,
)
[13]:
ktr_with_seas.fit(train_df)
2024-03-19 23:38:39 - orbit - INFO - Optimizing (CmdStanPy) with algorithm: LBFGS.
INFO:orbit:Optimizing (CmdStanPy) with algorithm: LBFGS.
2024-03-19 23:38:40 - orbit - INFO - Using SVI (Pyro) with steps: 301, samples: 100, learning rate: 0.1, learning_rate_total_decay: 1.0 and particles: 100.
INFO:orbit:Using SVI (Pyro) with steps: 301, samples: 100, learning rate: 0.1, learning_rate_total_decay: 1.0 and particles: 100.
2024-03-19 23:38:40 - orbit - INFO - step 0 loss = -2190.8, scale = 0.093667
INFO:orbit:step 0 loss = -2190.8, scale = 0.093667
2024-03-19 23:38:42 - orbit - INFO - step 100 loss = -4356.8, scale = 0.0069845
INFO:orbit:step 100 loss = -4356.8, scale = 0.0069845
2024-03-19 23:38:45 - orbit - INFO - step 200 loss = -4301.3, scale = 0.0071019
INFO:orbit:step 200 loss = -4301.3, scale = 0.0071019
2024-03-19 23:38:47 - orbit - INFO - step 300 loss = -4362, scale = 0.0072349
INFO:orbit:step 300 loss = -4362, scale = 0.0072349
[13]:
<orbit.forecaster.svi.SVIForecaster at 0x2b23a3550>
[14]:
predicted_df = ktr_with_seas.predict(df=df, decompose=True)
[15]:
predicted_df.head(5)
[15]:
| date | prediction_5 | prediction | prediction_95 | trend_5 | trend | trend_95 | regression_5 | regression | regression_95 | seasonality_7_5 | seasonality_7 | seasonality_7_95 | seasonality_365.25_5 | seasonality_365.25 | seasonality_365.25_95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2000-01-01 | 9.53352 | 9.61277 | 9.69350 | 9.50462 | 9.58387 | 9.66460 | 0.00000 | 0.00000 | 0.00000 | -0.02784 | -0.02784 | -0.02784 | 0.05674 | 0.05674 | 0.05674 |
| 1 | 2000-01-02 | 9.48100 | 9.56119 | 9.64121 | 9.50211 | 9.58229 | 9.66232 | 0.00000 | 0.00000 | 0.00000 | -0.07872 | -0.07872 | -0.07872 | 0.05761 | 0.05761 | 0.05761 |
| 2 | 2000-01-03 | 9.54230 | 9.62288 | 9.70269 | 9.50224 | 9.58282 | 9.66263 | 0.00000 | 0.00000 | 0.00000 | -0.01838 | -0.01838 | -0.01838 | 0.05845 | 0.05845 | 0.05845 |
| 3 | 2000-01-04 | 9.60186 | 9.68151 | 9.76075 | 9.50299 | 9.58265 | 9.66188 | 0.00000 | 0.00000 | 0.00000 | 0.03962 | 0.03962 | 0.03962 | 0.05924 | 0.05924 | 0.05924 |
| 4 | 2000-01-05 | 9.58472 | 9.66577 | 9.74660 | 9.50168 | 9.58273 | 9.66356 | 0.00000 | 0.00000 | 0.00000 | 0.02304 | 0.02304 | 0.02304 | 0.05999 | 0.05999 | 0.05999 |
Tips: there is an additional arg seasonality_fs_order to control the number of orders in fourier series terms we want to approximate the seasonality. In general, they cannot violate the condition that \(2 \times \text{fourier series order} < \text{seasonality}\) since each order represents adding a pair of sine and cosine regressors.
More Diagnostic and Visualization¶
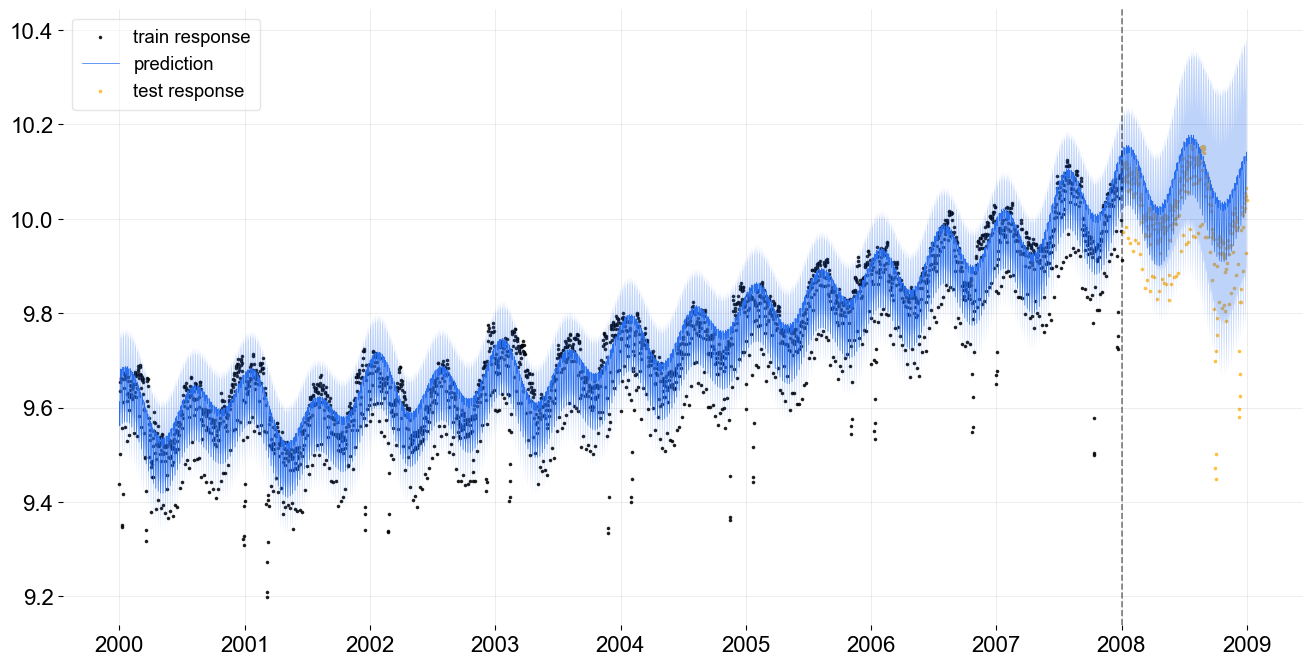
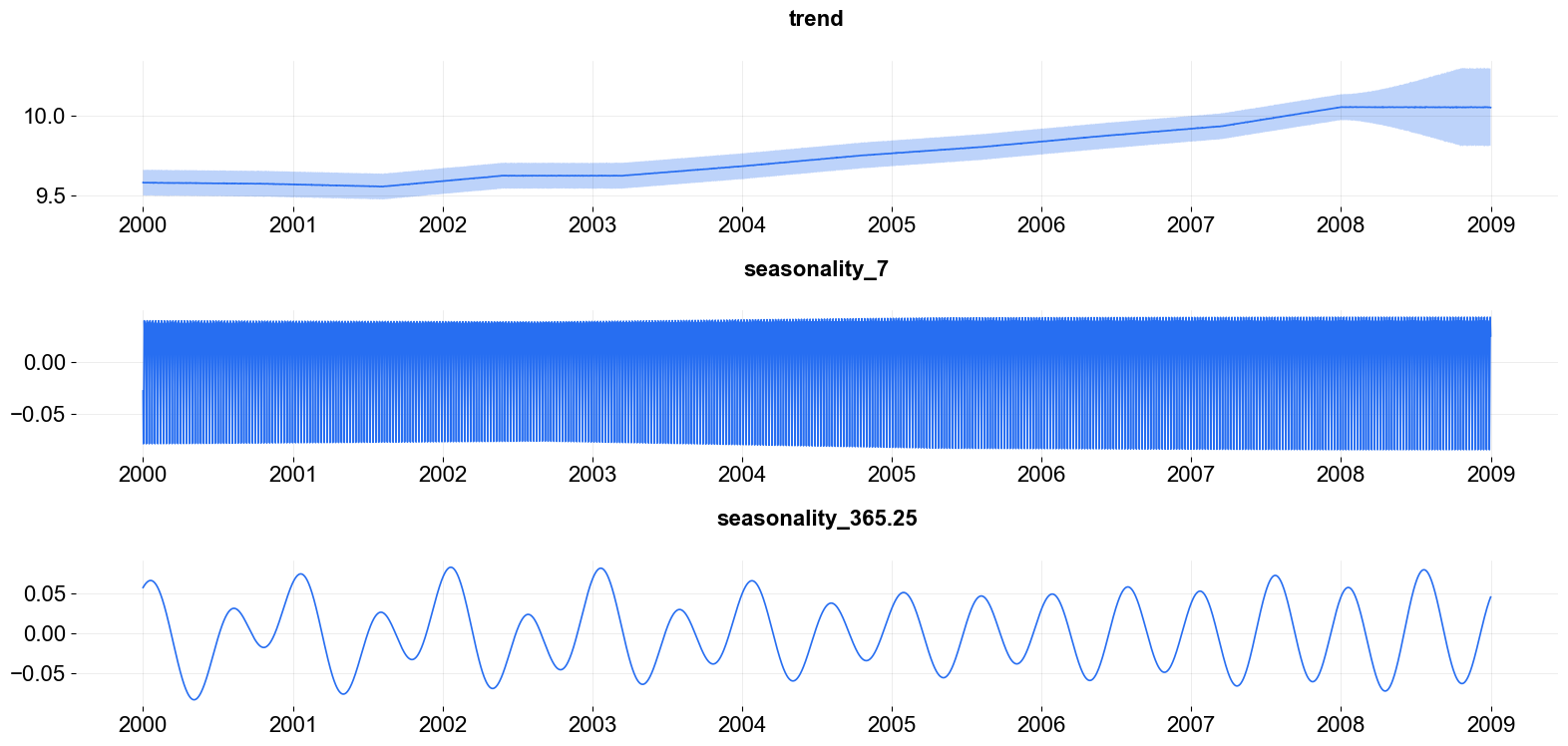
Here are a few more diagnostic and visualization. The fit is decomposed into components, the local trend and both periods of seasonality.
[16]:
_ = plot_predicted_data(training_actual_df=train_df, predicted_df=predicted_df,
date_col=date_col, actual_col=response_col,
test_actual_df=test_df, markersize=10, lw=.5)
[17]:
_ = plot_predicted_components(predicted_df=predicted_df, date_col=date_col, plot_components=['trend', 'seasonality_7', 'seasonality_365.25'])
References¶
Ng, Wang and Dai (2021) Bayesian Time Varying Coefficient Model with Applications to Marketing Mix Modeling, arXiv preprint arXiv:2106.03322
Hastie, Trevor and Tibshirani, Robert. (1990), Generalized Additive Models, New York: Chapman and Hall.
Wood, S. N. (2006), Generalized Additive Models: an introduction with R, Boca Raton: Chapman & Hall/CRC
Harvey, C. A. (1989). Forecasting, Structural Time Series and the Kalman Filter, Cambridge University Press.
Durbin, J., Koopman, S. J.. (2001). Time Series Analysis by State Space Methods, Oxford Statistical Science Series